上上個禮拜看到威廉大大在 DevOps conf 裡面發表了 Whoscall 的 Realtime Monitoring 經驗分享,下面這張圖其實勾起我不少回憶,尤其是過去快兩年的時間內,親身體驗架起來的一些東西,有些是我曾經在內部分享過的,想說應該也要分享一下給大家。
緣起
說來也蠻有趣的,當年使用 Graphite 的際遇其實是為了記錄 whoscall 的 Hitrate,而所謂的 Hitrate,一開始的需求是查詢有結果的次數/查詢次數來衡量服務品質,我加入時看到的架構是使用 Mongodb 去紀錄的:
1 | { |
每天產生一條紀錄,然後每個國家都記在同一個 document 內,這樣雖然解了燃眉之急,不過從這個架構來看,代表每接收一條 Request ,就要花一個寫入的IO,久而久之 Disk 的 IOPS 消耗加劇,而且如果同時有 TW 和 KR 的 Request 發生,還會有寫入競爭的問題,讓 API server 回應給 client 的速度更慢,再者,我們之後想要加入更多的資訊,類似到底是命中什麼,沒有命中的原因是什麼,就這樣不得不尋找更好的方案。
為什麼選擇 Graphite
在有這個問題後,我立刻向我的學長 @titanjer 求助,他其實是一個不世出的高人,整天看內容農場和尾隨正妹,但技術實力實在太過於強大,總是有很不錯的 solution ,而在求助後他給了我一句話:
Measure Anything, Measure Everything, You should use Graphite.
被當頭棒喝後,我開始疑問 Grapite 是啥?用這個有啥好處?
Graphite 好處
搜索之後發現了…
- RRD-liked service, 支援Metrics的精度遞減, 一天內10s一條, 七天內合成為1m一條, 一年內1hr一條
- 有豐富的查詢函數, sum/min/max/avg … etc
- 有完整的 ecosystem , , 簡單的 TCP/UDP 協議, 很容易可以插入數據
- 有完整的 HA & Scalable 方案 - Carbon-Relay
- 有數據 aggregator 方案 - Carbon-aggregator
- 支援 Restful-API, 可以利用 Grafana 顯示數據
- 簡單的配置方式, 只要會修改config, 就可以建構百萬數據收集的架構
- 非常多的公司採用
基本架構
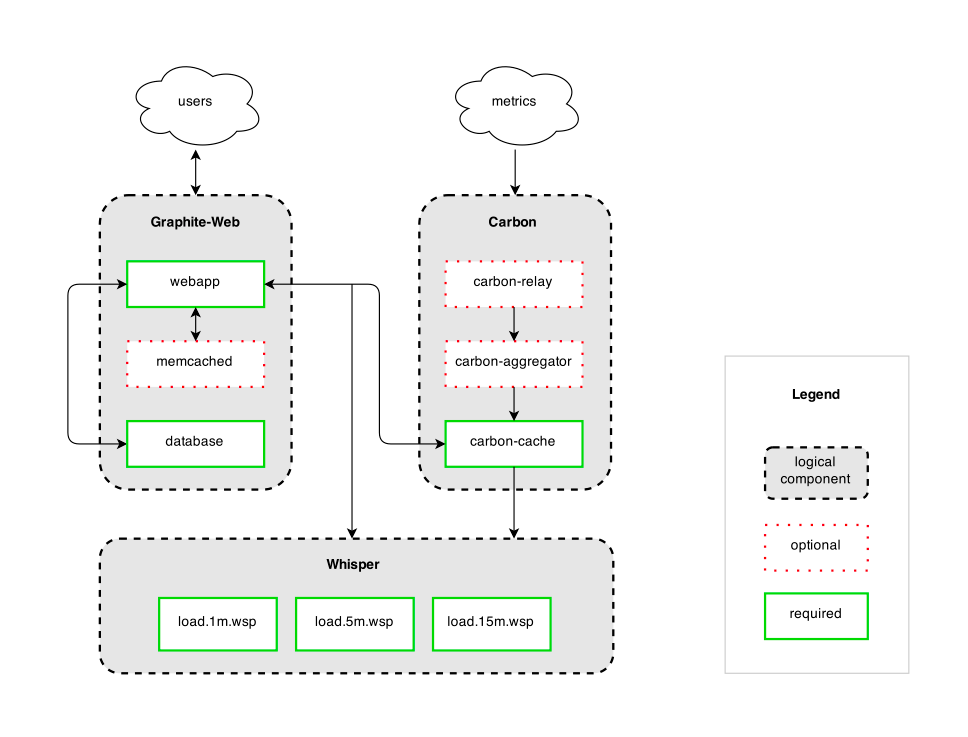
在架設前,先來搞懂架構長怎樣,這張圖我一直覺得畫得很棒,來自 whisper 的 github 頁面,基本上 Graphite 的組件共有三項:
- Carbon: 負責接受數據,把數據暫存到記憶體中
- Whisper: Graphite 專用的 RRD-style database,而且是 fixed-size databases,也就是根據你設定的 retention,建立出來的資料庫就是多大,好處就是很容易估算要多少 disk 空間,但根據我的經驗是 Whisper 其實儲存所需要的空間很少。
- Graphite-Web: 開放一堆API & Web UI 給你去存取資料
基本上 Carbon-cache 就是個queue的角色,會先把數據寫在 memory 裡面,等到時間到了後,一口氣 flush data 進到whisper,然後 Carbon 可以設定 MAX_UPDATES_PER_SECOND,預設是500,也就是一秒內呼叫多少次 whisper update 的 function ,這關係到你的 queue 內資料的多寡和 disk 的 IOPS,如果設定的太快,會導致 IOPS 上升,想要看資料也就是讀取時過慢(因為讀取有時候也需要做aggregation) ,而設定太低又會讓 queue 內的資料來不及寫入 disk ,詳細的說明可以看這篇minimizing-datapoint-lag-in-graphite。Whisper 基本上是 file based 的database系統,然後一個 time series 的 Metris 用一個 file 去紀錄,在每次寫入時都會去檢查 retention ,進而達成 RRD 的功效,Graphite-Web 則提供了 WebUI 還有一些 API 讓你去呼叫寫入的資料,當資料還在 carbon-cache 時,會直接去讀取 memory 內的資料,如果已經寫入 whisper ,則會去 disk 存取,當然也可以設定一些 cache,讓他不需要直接讀取 carbon 或是 whisper。
這邊順便提一下 Optional 的組件:
- carbon-relay: 拿來處理 HA 的,可以想成是個 Router ,設定後可以做到水平或是垂直 scale 數據儲存。
- carbon-aggregator: 這個套件可以先預先寫好一些 Rule ,例如你可以寫 PRODUCTION.host.*.requests 要直接存成 PRODUCTION.host.all.requests, 去減少寫入的維度。
- memcached: 這應該就不用提了,提供 API 那部份的 cache。
採用的Stack: Statsd + Graphite + Grafana
而後來採用的方法,其實是在 carbon 前面多塞一個 statsd 當作緩衝,主要原因是 server-side 想利用UDP 傳輸資料,而 Hitrate 這種屬於統計型態的資料,掉個幾筆其實並不會影響主要的趨勢,而利用 UDP 有個好處是,當 statsd + graphite 掛掉server 也不會因此而卡住, statsd 提供的 library 蠻全面的,並且是 nodejs-based 的,對於這種大量連接的工作,處理的效率很好,而且國外也有許多 production 的案例,這也是採用的原因。
紀錄的方法很簡單:
使用python statsd library,利用 incr 的呼叫去累加數字
1 | statsd.incr('TW.queryin.y') |
如此一來我們可以用1
sumSeries(TW.*.*) 來觀看總數是多少
再搭配 graphite 的 dashbaord,很簡單就可以看到下面這種圖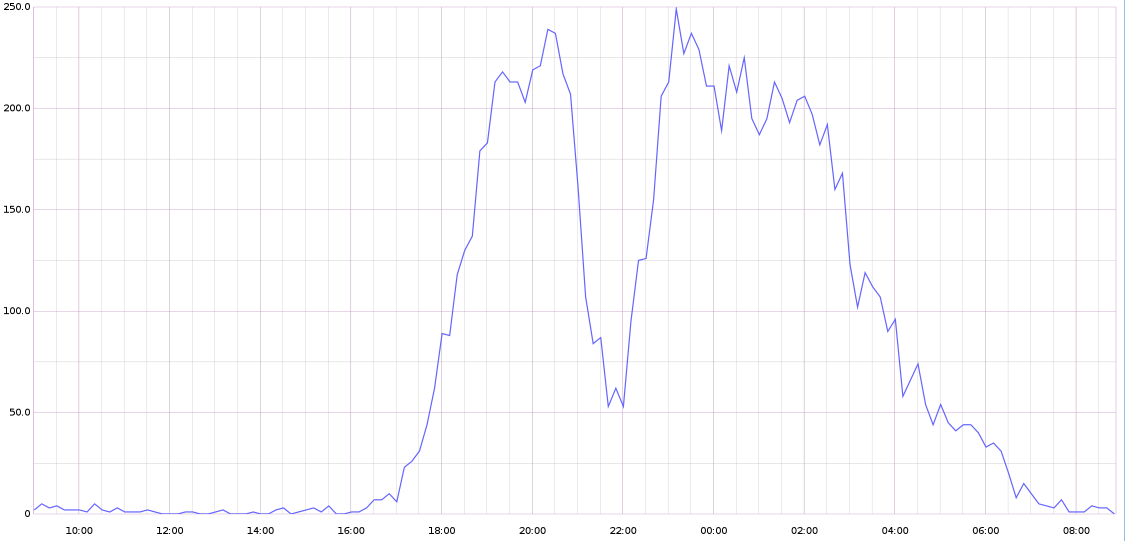
這邊也只是範例,當然實際的紀錄是比這個複雜許多,不過用這個方法,其實得到蠻多方便性和彈性,當然 API 的 performance 也有大幅的提升!
遇到的問題
當然在採用這個方案時,也是有些坑要注意
- Carbon-cache 還沒寫入完成就被關閉,queue 裡面的資料會掉,怕的話可以用 Carbon-relay 做 HA。
- 每個 Metric 都存在一個檔案裡面,當你要做 aggregator 動到太多數據時,其實是會同時打開這些檔案(想想看同時開啟1000個file)。
- Python 的 GIL 問題,導致只能用一個 core 跑,這對 aggregator 的效率也是有影響。
- IOPS 的不足,同問題1,因為寫入數據是寫到個別檔案,而 Whisper 每次最多才寫入 120 bytes,通常系統先會遇到IO-bound。
- Statsd 和 Carbon-cache 的 flush-interval 要同步,像我們是都用10s,這樣才不會寫入錯誤的資料,最下面會附上我的設定檔。
結語
其實我用 statsd + graphite + grafana 覺得蠻不錯的,因為太好用了,後來還有導入一些數據:
- application 層面去紀錄每個 API 的次數還有呼叫時間
- 每個 Queue worker 的執行時間還有 items 數量
- @suiting 大大還有幫忙導入 cloudwatch 的數據,因為cloudwatch 只能儲存2周的資料,而導入後我們就可以看經年累月的資料比較了。
最讓我驚艷的地方在於,從剛開始架設使用一台 AWS m3.medium 到現在,經過了一年半以上,公司的 request 量也早就成長一倍,居然還是非常堪用,CPU 使用率也維持在 25%~30% 中,Memory 大概吃 180 MB,然後到現在資料共佔了13GB,雖然紀錄的資料部份是有經過 sampling 的,不過總體而已還是看得出趨勢,搭配 Grafana 很容易就可以看出是否有異常。
設定檔
statsd
statsd/config.conf1
2
3
4
5graphitePort: 2003
graphiteHost: "127.0.0.1"
address: "0.0.0.0"
flushInterval: 10000
port: 8125carbon
storage-schemas.conf1
2
3[stats]
pattern = *
retentions = 10s:6h,10m:7d,1d:5ycarbon.conf1
2
3MAX_CACHE_SIZE = inf
MAX_UPDATES_PER_SECOND = 400
WHISPER_AUTOFLUSH = False