前言
大家都知道 RDBMS 其中有個主要的功能,就是能夠把 Transaction 這種任務,做得很完美,而 Transaction 這件事,在很多地方像是銀行轉帳或是進銷存的商業行為裡面,都是非常重要的,因為可以保證資料庫內的資料一致性。 而隨著 NOSQL 的蓬勃發展,看到很多 3rd party library 都想要在 application level 處理 Transaction 的議題,但往往好像使用者都沒搞懂,其實大部分的 lib 只有做到了 ACID 裡面的 Atomicity,而在多併發的環境下,不同的 transaction requests 其實是有機會把數據弄亂,這篇文章就是想要來複習一下 ACID 裡面 Isolation 這塊。
ACID 複習
ACID & RDBMS 的複習,推薦大家可以看看 COSCUP 2017 VanillaDB - 由淺入深的教學型 RDBMS,還有投影片
這邊也拿裡面銀行轉帳的例子,簡單講解一下:
1 | BEGIN TRANSACTION; |
Atomicity: all or nothing
如果 Transaction 只完成了一部分操作,像是遇到斷電或是資料庫掛掉,該 Transaction 會整個被取消,所有數據會透過日誌復原。Consistent:
在每一個操作的過程中,資料庫內的數據需要保持一致性,不會有 Transaction 執行到一半,去查詢資料時,資料庫內整體的餘額(balance)變成不一樣。Isolation:
就算每一個 Transaction 中有 Atomicity 的特性,但是無法保證在同時執行多個 Transaction 時,能夠保證整個資料庫的一致性,這時候就需要 Isolation 這個特性來幫忙。Duration:
資料庫內的資料不會因為斷電,系統崩潰而損失資料。
Isolation
前面提到就算有 Atomicity 的特性,但是在多個 Transaction 情況下,還是有機會把數據搞亂,例如下面這個例子:
Transaction 1 將 $100 轉入給 A
- 讀取 A 的值
- 這個值加上 $100 並寫回 A
如果在這兩個操作中,有個 Transaction2 也修改了 A 的值加上 $100
原本的結果應該是 A 增加了 $200 ,但實際上 A 最後很可能只有加上了 $100
這也是為什麼我們要為 database 加上 Isolation,這樣才能讓 database 在修改數據時維持一致性,一般討論 Isolation 有數種隔離級別,其實基本上就是上鎖的概念,而鎖的顆粒度大小不一樣。
分為四個級別:
- Read Uncommitted
- Read Committed
- Repeatable-Read
- Serializable
為了瞭解這些級別的差距,我們必須要討論一下各個級別解決的問題是什麼。
Read Uncommitted
最一開始時,想要解決的就是兩個以上不同的 process 對同一筆數據做改變,而最基本的解決方法就是建立排他鎖 (eXclusive Locks or 寫鎖)
- 啟動 Transaction A 時,該筆數據只能被此 Transaction 修改
- 其它 process 只能讀取
這個級別我們就稱為 Read Umcommitted
Read Committed
有了 Read Umcommitted 後,事情可沒就這樣結束了,後來大家馬上就發現到,如果 Transaction A 將某個值改變到一半,又把它 rollback 回去,這樣其他的 process 有可能讀取到錯誤的值,接著又把這個錯誤的值 commit 就糟糕了,這就是所謂的 Dirty Read,也就是讀取到還沒 commit 的值。
Dirty read1
2
3
4A update field1
B read field1
A rollback
B commit
這個時候其實只是需要調整鎖的程度,對於需要修改的數據,加上寫鎖後,需要到整個 Transaction 結束後才會釋放,而對於單純讀取 (SELECT) 的數據就沒有那麼嚴格,一但在 Transaction 內讀取完就釋放讀鎖。
Repeatable-Read
這個級別主要是要解決 Unrepeatable read 的情況,當我們需要在一個 Transaction 裡面讀取同個 field 時,有可能會讀到不一樣的值, 情況有可能是這樣發生的,當 Transaction A 在讀取 Field1 時,同時間 Transaction B 改變了這個該值,當 Transaction A 再次讀取該值時,其數據就有可能被改變,這也是因為 read lock 會在 SELECT 完後馬上就被釋放,所以最簡單的方法就是把讀寫鎖釋放的時間延後到 Transaction 結束後,但壞處就是系統的效能會下降的很快,連讀取資料的部分也需要排隊讀取
Unrepeatable read1
2
3
4A read field1
B update field1
B commit
A read field1
Serializable
最高的級別,一般資料庫不會使用到這個級別,而這個級別是要解決 phantom read 的問題,主要跟 Range query 比較有相關,舉例來說,當 Transaction A 使用 range query 查詢後得到 10 筆資料,而 Transaction B 在這個條件裡面新增了一筆資料並且 commit 後,Transaction A 在去 query 時,就會變成 11 筆資料。
但使用這個級別,最簡單的做法基本上就是鎖住整張表,以免不同的 Transaction 更動其資料,所以造成的效率低落也是可以想像的。
phantom read1
2
3
4A query => 10
B insert 1
B commit
A query => 11
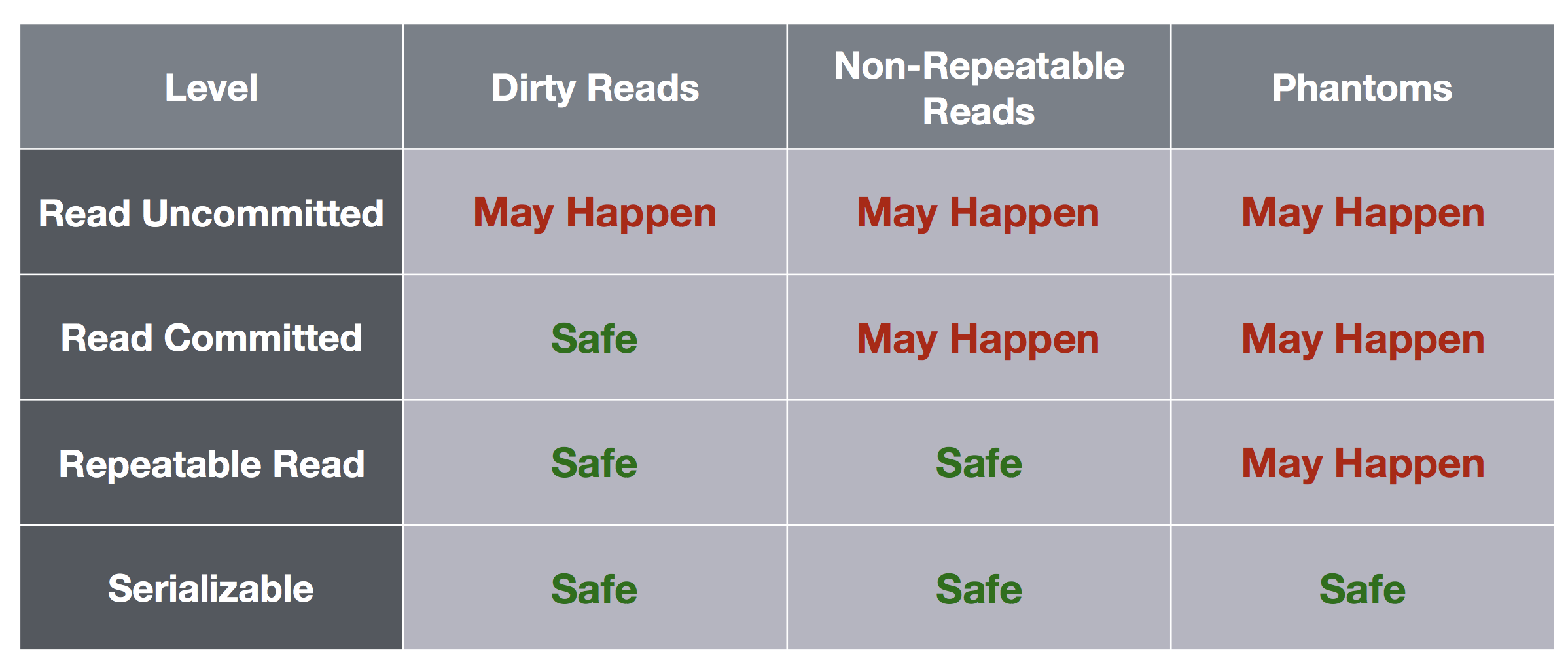
總結一下 isolation & lock 的關係
from wiki
| Isolation level | Write Operation | Read Operation | Range Operation |
|---|---|---|---|
| Read Uncommitted | until commit | not used | not used |
| Read Committed | until commit | during statement | not used |
| Repeatable Read | until commit | until commit | not used |
| Serializable | until commit | until commit | until commit |
順便借用一下 Yu-Shan Lin 大大的投影片的圖
結語
複習了一下 RDBMS 的 ACID 概念,其實發現在提升 concurrency 的情況下,又要讓數據保持完整,其實是一件很困難的事情,而其實還有很多東西像是 MVCC、Row version、樂觀鎖、悲觀鎖還有死鎖等等東西,這篇都還來不及贅述,要實作真正的 Transaction 在 application 端其實是很複雜的,而 RDBMS 其實都很好的幫我們處理完這些問題,所以要處理數據且需要 Transaction 的話,還是推薦交給專業的工具,而不要自己傻傻的刻一套啊。
Reference
- https://en.wikipedia.org/wiki/Isolation_(database_systems)
- https://www.zhihu.com/question/30272728
- https://technet.microsoft.com/en-us/library/ms187101(v=sql.105).aspx