這篇速記主要紀錄看了 AWS reinvent 這個影片的心得,裡面講解怎麼 tuning TCP 相關的 networking issue,影片來源在此
相當推薦這個影片,裡面不僅提到一些 TCP 上面的學術名詞,也很實際的告訴你在 linux 上面怎麼改變那些值,然後還可以看到在 application 的 benchmark 有很大的差距,這是我之前想像不到的,居然更改了一些設定可以有那麼巨大的差別。
Preface
講到 TCP ,講者一開始打賭大家第一個想到的,一定是 3 way handshake,一定是 SYN-ACK,但其實 TCP 很棒的地方在於,它提供了一個抽象層,然後我們不需要知道中間到底 packet 發生什麼情況,TCP 會幫忙處理類似重傳,還有要送多快不會掉包的問題,盡最大的可能讓 packet 到達目的地,並且保證封包到達的順序性。
- TCP does well on flow control
- it makes sure it sends as many packets as it can without overwhelming the receiver.
TCP optimization
主要有幾個重點
Receive Window
接收端的流量控制

傳送數據的時候,如果對方收不下那麼多封包,就會產生 packet drop 的現象,為了避免這種現象發生,接收方要回報自己的 Receive Window (RWND) 有多大,傳送方知道了這個數值後,才不會多送封包過去造成浪費。而 Receive Window 基本上跟接收方開多少 Receive buffer 有關,在 linux 這邊可以用 sysctl -a 去查 RWND 的大小
sysctl -a | grep memnet.ipv4.tcp_rmem = <MIN> <DEFAULT> <MAX>
有些人會遇到明明網卡很強,網路 bandwidth 也很大,尤其在內網的情況,為什麼網路速度還是上不來,有時候其實只是這個值在搞鬼。
而另外一點是,RWND 要設定到多少才是合理?設太大會吃掉太多 linux 的 Memory,設太小又會造成接收資料堵塞,實際上 RWND 的正常值是跟BDP 有相關,也就是跟 bandwidth 和 RTT (round trip time) 有相關,RTT 是指兩台主機間的延遲,你發出 request 後過了多久收到 response 基本上就是 RTT。
BDP 的公式,假如 bandwidth 是 100Mbps,而 RTT 是 100ms1
BDP = 100Mbps * 100ms = (100 / 8) * (100 / 1000) = 1.25MB
在這個公式中,接收端 in-flight 就可以吃下 1.25MB 的資料,所以 RWND 不應該設定小於 1.25MB
Congestion control
傳送端的流量控制
傳送端也可以做流量管制,因為 RWND 只有反應接收方的電腦狀態,而沒辦法確切代表整體網路,而且現在網路的的品質其實差距很大,像是 wifi,4G/5G 和有線網路就有很大的差別,所以傳送端這邊也有非常多的演算法,來推導發送多少的 packet 才會是最好的,減少半途消失的損失。
這邊演算法有根據不同的情況而產生的設計
- Packet LOSS
- Latency
- Bandwidth
TCP slow start
TCP slow start 的概念就是一開始先送小一點的資料量,再慢慢增加到會掉包的程度,最後在減少發送量,以期找到最佳的傳輸大小,這邊就引入了一個值叫做 Congestion Window (CWND),透過更改 CWND 的大小去找到最佳值。

印象中 linux 舊版的 init CWND 是 3MSS,新版的 init CWND 則是 10MSS,一個 MSS 是 1448 bytes。
這邊有個例子讓大家感受一下 CWND 大小的影響,現在有個網頁是 20KB,如果是 3MSS(4.2KB),在不考慮 CWND 會改變的情況下,需要發送將近 5 次,而改成 10MSS 則可以大幅降低傳輸次數。
Loss
Loss 會造成 throughput 下降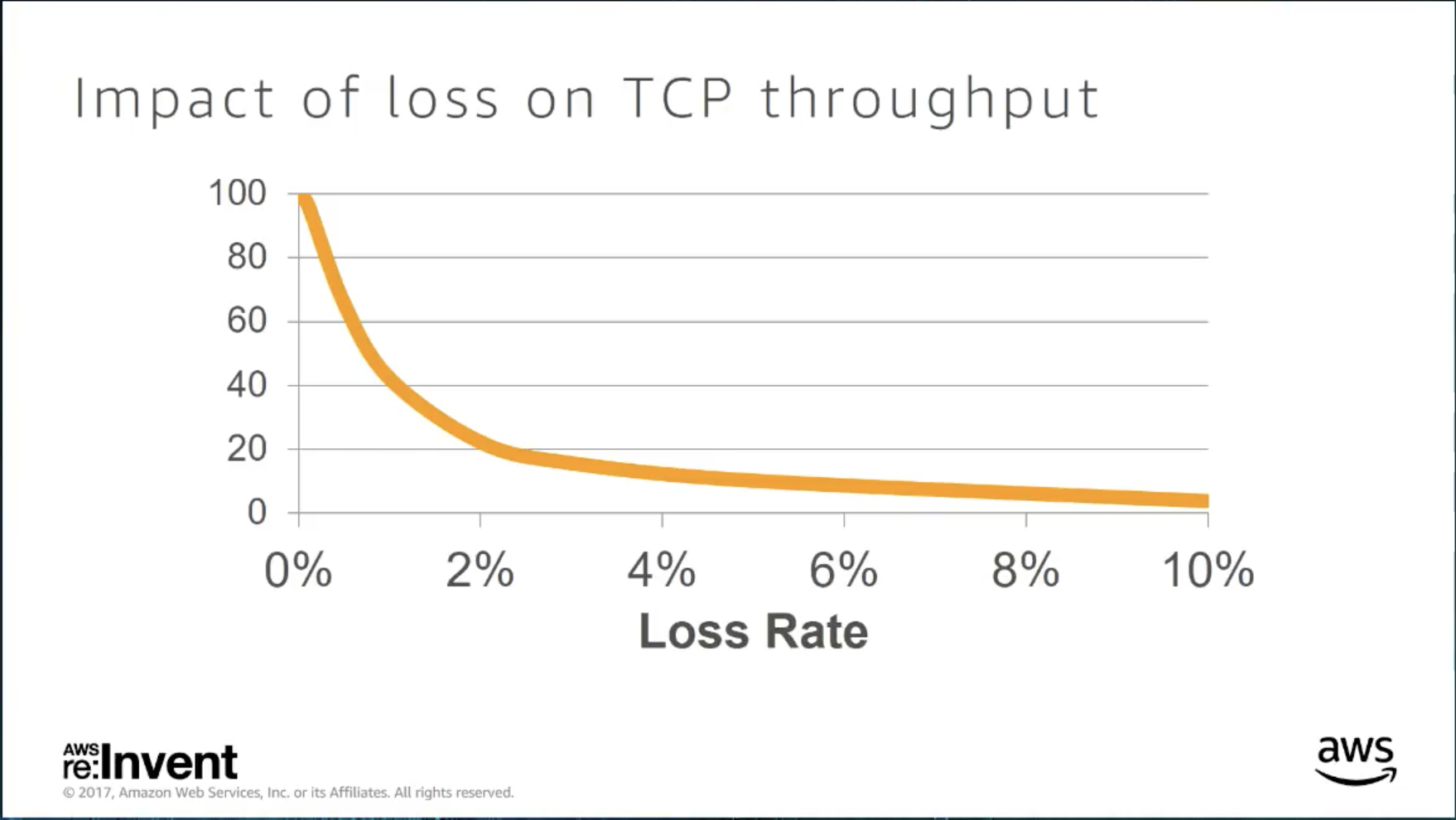
可以透過觀察 TCP retransmissions 看有沒有 loss 發生1
netstat -s | grep retransmit
但是這個指令不太好用,因為無法看到是哪個 TCP 連線造成的,也沒有時間的資訊,只能靠一直 polling 去畫圖才會比較好用。
取而代之的是用 socket level 的 debug tool
使用 ss -ite 可以看到更多的資訊
1 | send-Q: 多少資料在 queue 裡面需要被送出,如果這個值是0,有可能是 application 裡面就卡住了,大於 0 才會是正常的 |
另外這個影片有提到一個 tool 叫做 tcpretrans
made by netflix brendangregg 可以拿來即時監控 retransmission
Congestion Control Algorithm
Cubic: 2.6.19+ 目前我看我手上的 ubuntu 都是預設使用這個
Other algo: BBR, Vegas, illinois, Westwood, Highspeed, Scalable
Retransmission Timer
封包掉時,要經過多久才重送
- 太低: congestion control 反應過度,而且重傳無法改善問題,只會造成網路更壅塞
- 太高: 增加 latency
Others
TC (traffic control) 可以製造一些 loss,還可以更改 qdisc 去做一些 network performance 測試
MTU: maximum transmission unit 在 VPC 內的 EC2 可以使用 Jumbo Frame 來溝通,使用 MTU 9001 會幫助蠻多的
Experiment
最後有個簡短的 experiment result
case 1. Http with intermediate network loss

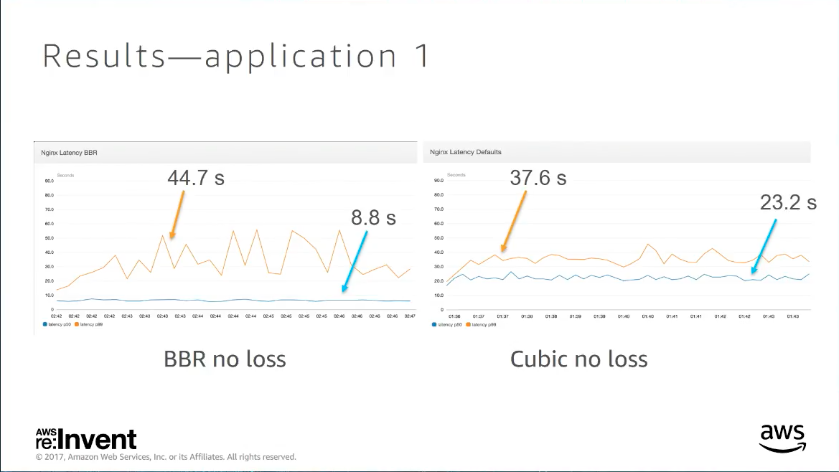
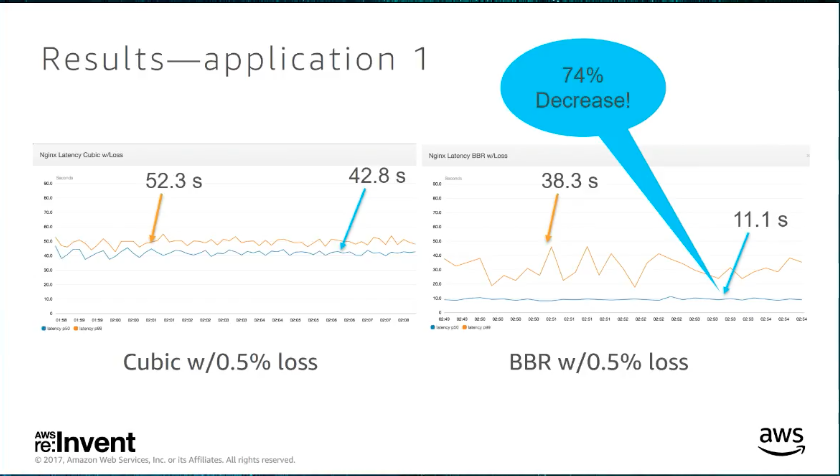
更改 TCP-BBR 不管在有無 loss 的情況下,拿來跟 cubic 對比,p50 都好上不好,不過 spike 其實會變多
case 2. low RTT between servers

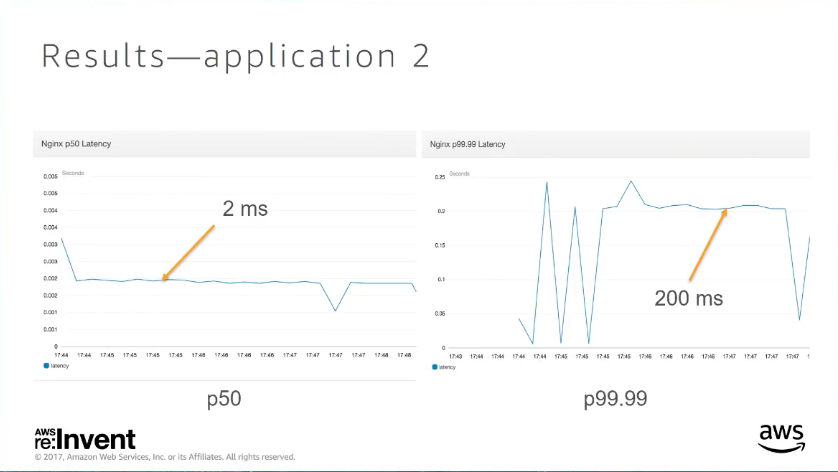
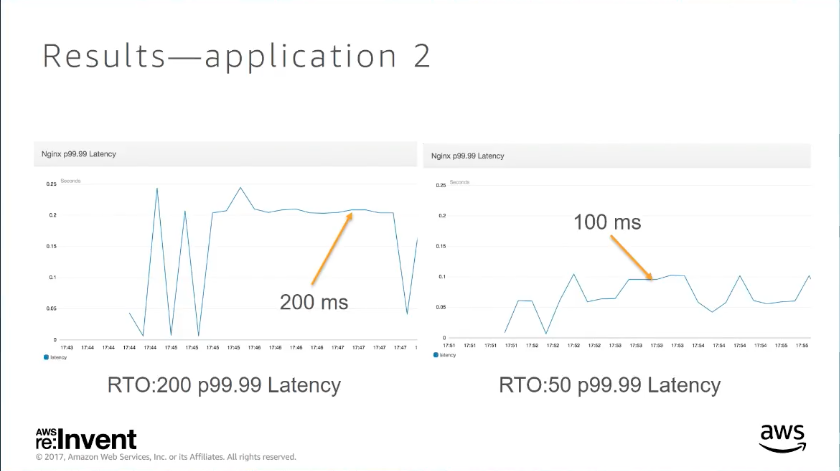
更改 RTO 對 request 的 p99.99 有巨大的改善
case 3. High transaction rate HTTP service


更改 init CWND,p50 latency 改善也很多,但是要注意需要的 Bandwidth 也會有所改變
Reference
圖片來源來自這本很棒的書
https://hpbn.co/building-blocks-of-tcp/#congestion-avoidance-and-control