Random Scheduler Note
Golang Scheduler
最近因為 golang 討論區的一篇文章,又簡單複習了下 golang scheduler,其實這個 scheduler 設計上面算是蠻簡單的,具體的內容其實很多文章都寫過了,而特點就是讓多個 goroutines 跑在 OS thread 上,是個 M:N 的分配,盡量減少了 OS thread 的建立,進而減少 OS thread 昂貴的 context switches 時間,runtime scheduler 則根據一些規則 (local, global runnable job & work stealing) 負責把 goroutines 分配給對應的 OS thread,並且在特定時機切換 core 的擁有權,讓 goroutines 們看似能夠平行運作。
不過我其實是知道不同的 goroutine schedule 到同一個 OS thread 上面,還有一個潛在的好處就是,不同 goroutine 間的共享變數,能夠善用 L1/L2 cache,而在現今的 NUMA 架構下的 CPU,這方面對於 scheduler 的效能還是有蠻大的影響,不過查了下其實在 2014 年 google 的 Dmitry Vyukov 就有在提 NUMA-aware scheduler for Go,不過一直沒有完成,也就是說現在的 scheduler 只是被動得到了一些好處,並不是完全考慮硬體架構的 scheduler。
NUMA-aware Scheduler
而輾轉又看到 Netflix 也有相關的 NUMA-aware scheduler 的文章,不過是針對不同的 heterogeneous workload 去設計,一般來說 Linux 上面的 CFS 只是幫我們很公平的分配 cpu 給不同的 process,剩下的都需要 application owner 自己去手動調整,像是 priority or cpu affinity 之類的設定,這篇文章則是在提了一個範例,如果 container A 是 cpu intensive,container B 是 latency-intensive,則應該把 container A 趕去不同的 NUMA socket,減少 cache thrashin 的機率。
For example if we predict that container A is going to become very CPU intensive soon, then maybe we should run it on a different NUMA socket than container B which is very latency-sensitive. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
而底下這張圖很好的解釋了,該怎麼去 allocate A & B container 才是好的 resource 使用方式。
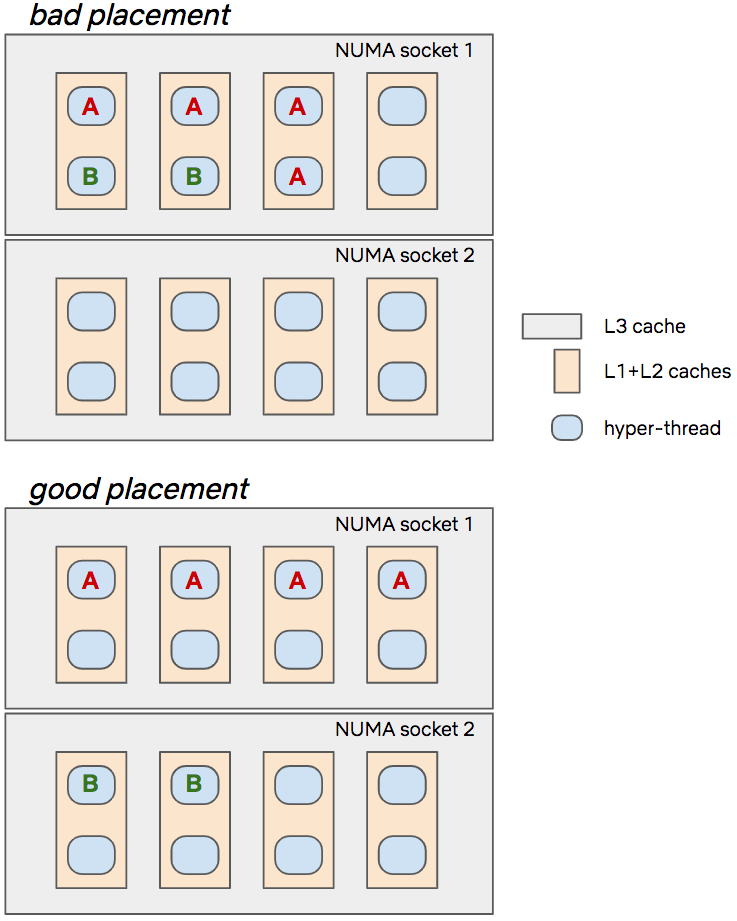
from https://netflixtechblog.com/predictive-cpu-isolation-of-containers-at-netflix-91f014d856c7
而 Netflix 更進一步的去想怎麼樣自動化這件事情,也提到 resource allocation 是個經典的數學問題。
Resource allocation problems can be efficiently solved through a branch of mathematics called combinatorial optimization, used for example for airline scheduling or logistics problems.
最後 formulate 成線性規劃的問題,也把相關的演算法實作在 cgroups 上面,並且 opensource titus-isolate 了出來。
心得
其實 Netflix 這篇文的圖文解釋很棒,也告訴我們怎樣的標準來 schedule Numa-aware task 是好的,畢竟很多人都沒有用 data center 那麼大的機器,而有這些知識,去手動調整我們的程式可能也是不錯的解法。
- avoid spreading a container across multiple NUMA sockets (to avoid potentially slow cross-sockets memory accesses or page migrations)
- don’t use hyper-threads unless you need to (to reduce L1/L2 thrashing)
- try to even out pressure on the L3 caches (based on potential measurements of the container’s hardware usage)
另外是 scheduler 的演算法和論文很多,還是要看解決的問題和 workload 是什麼,找到評量的目標和 loss function,才能真的去設計一個演算法。